Pipeline Improvements & Course Progress Update
A few quick lab updates:
Pipeline Improvements
You might have noticed that some of the daily idea posts this week felt pretty similar (e.g. AI agents need ID cards and Your AI doesn't have an ID).
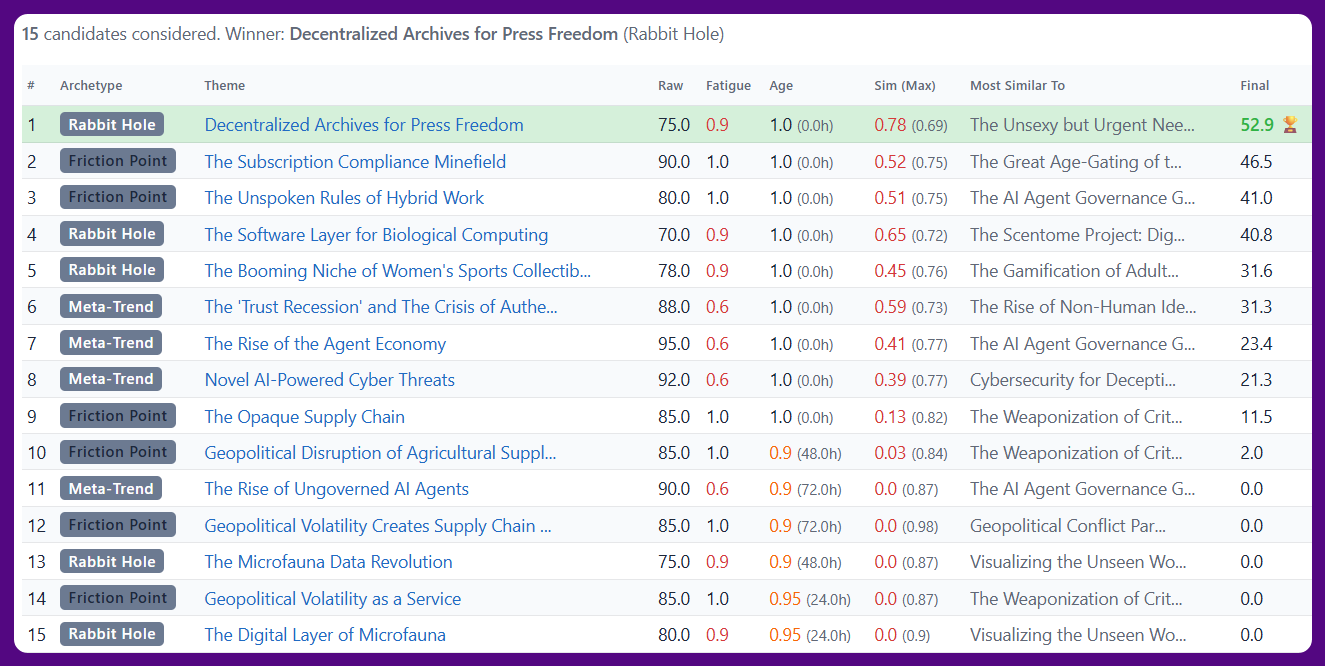
The root cause for this was pretty simple: Each day, the pipeline picks the 3 best ideas (one per archetype: meta-trend, friction point, rabbit hole) from a 4 day rolling window of business signals from the news. But some themes (like AI agent security) are so dominant in the current news cycle that they keep bubbling to the top, resulting in similar ideas each day. Most of these automatically get rejected for being too similar to recent posts. Even the 2-3 surviving ideas are heavily penalized for similarity, but since these are all we have to work with, the pipeline picks the least bad one and proceeds to developing it into newsletter post.
The fix was two-fold:
- The pipeline now generates 9 ideas each day, 3 per archetype. This inherently lets less dominant (but still high-signal) insights rise to the top and join the candidate pool. I also did some prompt engineering to avoid the consensus trap and ensure each of the 3 ideas per archetype are radically different from each other.
- I also added a negative prompt that injects recently published ideas, so the Synthesis step should now deliberately avoid these.
Based on what I'm seeing in the data, this fix seems to work as expected. I'll keep an eye on it over the next week. The pipeline had been humming along nicely since I launched GammaVibe 11 weeks ago, so some level of tuning isn't unexpected at this stage.
Course Progress Update
I finished recording The Agentic Pipeline course — and it was a different beast from anything I've recorded before. Unlike a traditional, deterministic coding tutorial, where you can plan each talking point in advance, agentic engineering doesn't give you that luxury. Even though I had built the pipeline twice already (once in production, once as a dry-run for the course) and had a clear end state in mind, I admit I was a bit nervous about working through this live on camera. I had to debug issues in real-time when needed and decide when to request changes or continue on to the next step.
I also had to find the right balance between outcome-oriented prompts (describing what the result should look like) and prescriptive ones (specifying how to get there), since I wasn't just building the pipeline myself — I also had to consider students building their own in parallel.
But I was able to organically touch on everything I had planned to cover. I walk through the full pipeline build, including podcast creation. I discuss and demonstrate when and how to use embeddings and vector similarity search, how to leverage synthetic data, robust error handling, and more.
Now I'm editing everything over the next few weeks and then building a proper course (with quizzes and accompanying materials) on the course platform.
Super excited to be able to share this with you when it's ready!
In the meantime, if you want a head-start on the concepts, grab the blueprint here: https://gammavibe.com/blueprint.